
Per anni abbiamo confuso la produttività con la velocità di digitazione: più framework, più scaffolding, più snippet, più “output”. In realtà era semplcie data entry: un lavoro prezioso, sì, ma spesso meccanico.
Con gli agenti AI (e con strumenti come Claude Code di Anthropic ) sta succedendo una cosa molto più radicale: il costo di produrre codice sta crollando. E quando qualcosa diventa economico, il valore si sposta altrove.
Oggi il collo di bottiglia non è più “scrivere”, ma capire, verificare, scegliere.
Dal coding alla capacità di valutazione: il nuovo collo di bottiglia è il code review
Gli LLM possono generare tantissimo codice in pochissimo tempo. A volte il risultato è ottimo, a volte è quasi ottimo, ed è proprio lì che diventa pericoloso.
Le imperfezioni non sono quasi mai “vistose” come una sintassi sbagliata. Sono più subdole:
- assunzioni implicite non dichiarate
- edge case ignorati
- sicurezza data per scontata
- regressioni silenziose
- complessità che cresce senza che nessuno se ne accorga
E quindi il lavoro si sposta: da produrre a validare.
Il code review smette di essere un passaggio di processo e torna a essere quello che dovrebbe essere: un filtro di verità.
Caso reale: un progetto personale che riparte grazie alla “programmazione automatica”
Negli ultimi mesi ho avuto modo di testare in modo molto concreto l’uso degli Agenti AI per il codice.
Avevo un progetto personale arenato. Non perché fosse impossibile, ma per un motivo banalissimo: mancanza di tempo e (soprattutto) mancanza di voglia di scrivere codice dopo una giornata lavorativa già di per se intensa.
Poi ho iniziato a usare Claude Code con un’idea semplice: “se posso delegare la parte più meccanica, magari riesco a rientrare nel progetto senza bruciarmi”.
Ed è esattamente quello che è successo.
La sensazione è questa: la barriera psicologica non è più “oddio devo mettermi a scrivere 400 righe stasera”, ma diventa:
- “scrivo una specifica chiara”
- “faccio generare una prima implementazione”
- “revisiono, correggo, indirizzo”
- “raffino la specifica e ripeto”
Il mio workflow si sta spingendo sempre più verso due attività:
- Specializzazione delle specifiche
Non “fammi un endpoint”, ma: vincoli, casi limite, error handling, performance, logging, sicurezza, test. Più la specifica è precisa, più l’agente smette di indovinare. - Code review come attività primaria
Io non sto “cedendo il controllo”: lo sto concentrando. Il controllo si sposta dalla tastiera alla revisione. E paradossalmente mi sento più autore, non meno.
Risultato: un progetto che era fermo da mesi sta prendendo vita. Non perché l’AI “fa tutto”, ma perché abbassa l’attrito abbastanza da farmi restare nel flusso. Lo dimostrano anche i grafici di attivita’ sul mio GitHub:
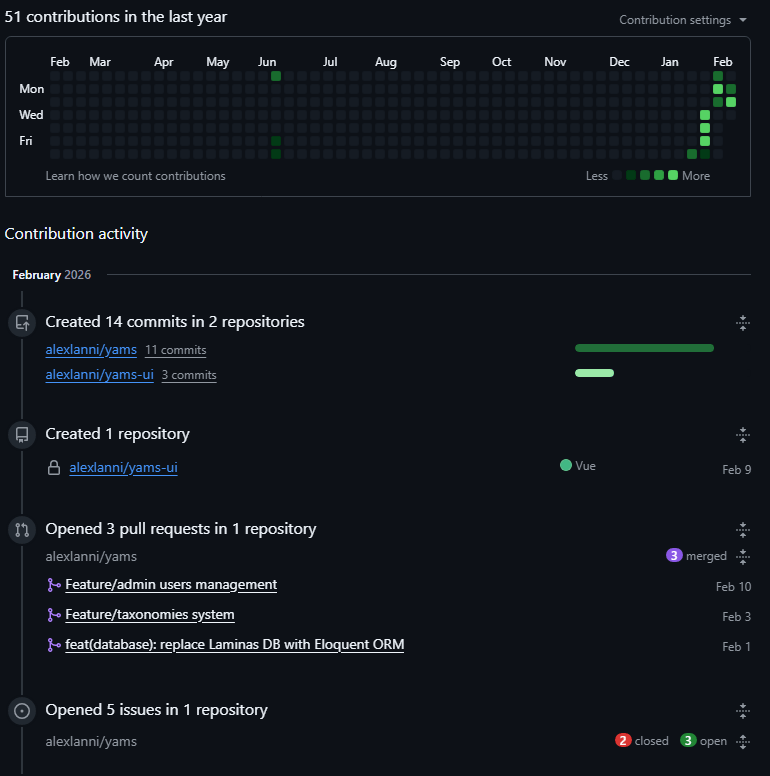
Il prossimo passo: codice auto-revisionato… e allora cosa resta a noi?
È abbastanza evidente dove sta andando il trend:
- agenti che generano codice
- agenti che scrivono test
- agenti che fanno static analysis
- agenti che propongono refactor
- agenti che fanno review preliminari prima ancora che un umano guardi la PR
A quel punto, il valore umano diventa ancora più raro e più importante:
decision making, responsabilità, contesto, etica, trade-off, qualità.
E qui si apre la parte “filosofica”: quando acceleri tutto, rischi di accelerare anche gli errori, la superficialità e la pressione.
Proprietà intellettuale: chi “possiede” cosa, quando il codice lo scrive un agente?
La tutela del diritto intellettuale diventa uno dei temi centrali dei prossimi anni, perché qui non parliamo solo di “copyright del codice”, ma di un insieme di rischi pratici:
- Contaminazione di licenze: output che richiama troppo da vicino codice terzo (anche involontariamente).
- Segreti aziendali: cosa finisce nel prompt? cosa viene loggato? per quanto tempo rimane?
- Attribuzione e responsabilità: se un bug critico nasce da codice generato, chi risponde davvero?
- Derivazione: quanto deve essere “simile” un output per diventare problematico?
La risposta non è “non usare gli agenti”, ma usarli con governance: policy interne, review obbligatorie, check automatici, strumenti SAST/DAST, controllo sulle dipendenze, e soprattutto disciplina su cosa si invia al modello.
E Claude Code, lato dati, cosa garantisce agli utenti paganti?
Qui vale la pena essere molto concreti e basarsi su ciò che Anthropic dichiara ufficialmente.
- Per i prodotti commerciali (Team/Enterprise/API), Anthropic dichiara che di default non usa input/output per addestrare i modelli. (privacy.claude.com)
- La documentazione di Claude Code spiega che la retention e l’uso dei dati dipendono dal tipo di account e dalle preferenze; per gli utenti consumer esistono opzioni (es. opt-out dal “model improvement”) e finestre di conservazione differenti. (code.claude.com)
- Anthropic descrive anche l’esistenza di accordi di “zero data retention” che si applicano ai prodotti che usano una Commercial organization API key, includendo esplicitamente Claude Code. (privacy.claude.com)
Tradotto in pratica: se stai lavorando su codice sensibile, la scelta dell’account/chiave (consumer vs commerciale) e le impostazioni di privacy non sono dettagli, sono parte dell’architettura del tuo workflow.
La domanda che vale più del tooling
Se la produttività esplode e la “produzione di codice” smette di essere un fattore distintivo, allora la domanda non è “quanto possiamo costruire”.
È: perché lo stiamo costruendo?
Stiamo inseguendo solo più feature, più margine, più velocità… o possiamo permetterci un cambio di metrica?
Possiamo scegliere di rallentare, aumentare la qualità, ridurre la frenesia e riportare l’epicentro sull’uomo: sostenibilità, cura, responsabilità, impatto reale?
Quando il codice diventa facile, la parte difficile diventa scegliere cosa vale la pena fare.

Lascia un commento